
Editique + Open Source = ? (la cuisine...)

Dans mon premier post de la série Editique et Open Source j'expliquai pourquoi j'estimai nécessaire le recours à des composants ouverts pour créer une solution éditique :
 Cysiph
Cysiph
Dans le second post de cette série j'attaquai le comment avec les formats d'entrée et de sortie :
Cyril Stouck
Allez on attaque le cœur du sujet : comment on fait tout ça avec des briques ouvertes (ça fait 15 jours qu'on attend mon gars). Je vais illustrer le modus operandi avec ce schéma :
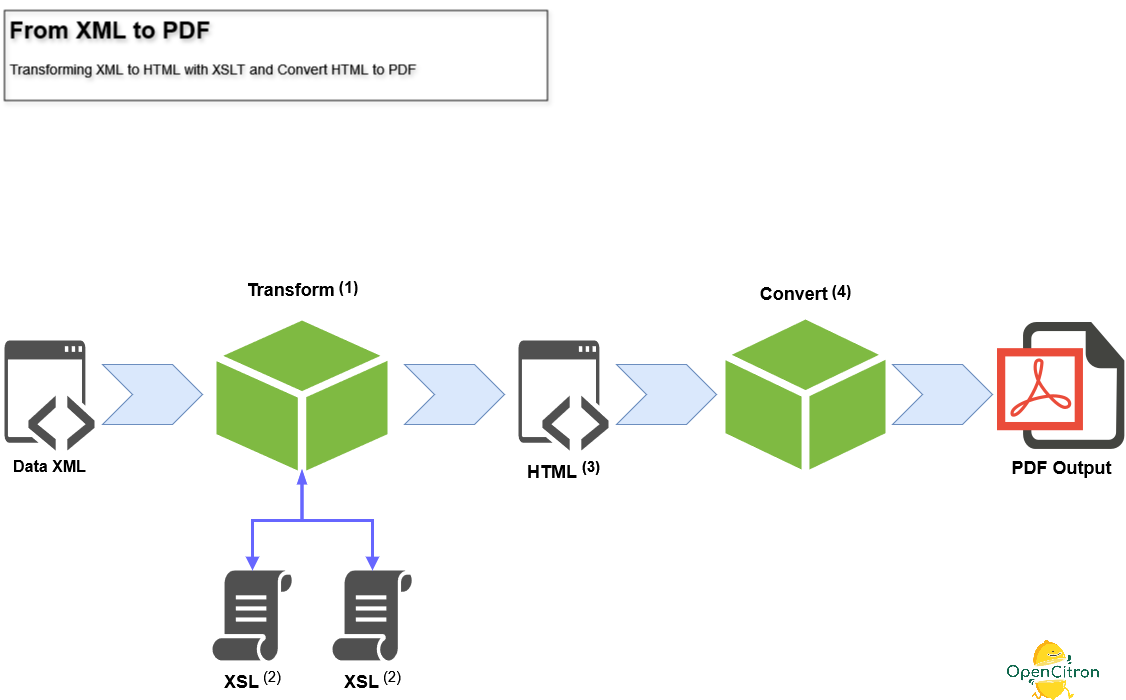
1 - Transformer : XSLT
ou comment on passe d'un flux de données XML à un document HTML
Avant de me lancer j'imagine que certains sont déçus de voir arriver HTML comme format intermédiaire : scandale, trahison, grand n'importe quoi, ... Je décrirai plus tard pourquoi et comment une page web, si elle est bien conçue sera notre atout majeur.
XSLT quesako ? XSLT est un des 3 éléments de la spécification XSL, issue comme HTML et XML du W3C; elle date de 1999 !
XSL est composé de 3 parties :
- XSLT : langage balisé basé sur XML pour transformer (on y est) un flux XML entrant, en un autre format de sortie de type texte : XML, HTML, texte, SVG, XSLFO.
- XSL-FO: grammaire XML décrivant un document imprimable via un processeur. FO : Formatting Object. Le processeur en question attend un flux XML (éventuellement généré via XSL) à la sauce FO pour générer une sortie : écran, PDF, Postcript... Le processeur le plus connu est FOP de la fondation Apache. Il est toujours en vie et continue d'évoluer. XSL-FO, ou FO pour les intimes, pourrait très bien être le maillon central à la place d'HTML, car il est réellement dédié à générer des documents, mais sa maîtrise est plus complexe que HTML et ses amis (cf. plus bas)!
- XPath : pour faire simple c'est le SQL du XML. Cela permet de requêter un arbre XML pour filtrer ou compter des nœuds. C'est le compagnon le plus fidèle de XSLT.
Par la suite je mélangerai XSL et XSLT pour parler du format de fichier et de la transformation elle même.
Dans notre monde idéal, on retrouvera uniquement XSLT et XPath.
XSLT est donc un langage xml, qui permet de parcourir un document XML pour générer une sortie. On peut faire des calculs simples ( sum, count, ... ) des conditions (if, switch ) , des boucles for sur une partie de l'arborescence, appeler des sous modèles, ... Je l'utilise pour tout : facture, slides avancement de projet, fiche de tests, ... Un fichier XSL est souvent appelé (à tort je trouve) une feuille de style. Voici un petit exemple de fichier xsl :
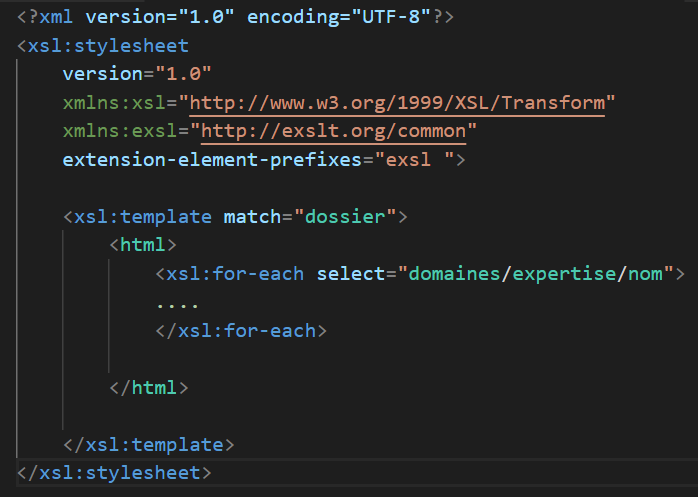
Je décrirai plus loin les arcanes de XSL. Pour faire fonctionner tout cela, i.e transformer notre XML en autre chose, 2 grandes solutions :
- associer directement le document xml à une feuille de style dans le corps du xml lui même : <?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="xsl/competences.xsl" ?>
- passer par une api pour charger le xml, le xsl et générer la sortie.
La première solution est simple à mettre en œuvre, on la garde pour les tests, les pocs, le débugage, le preview, mais elle ne permet pas facilement de récupérer le HTML.
Pour les APIs, c'est open bar, les grands langages ont tous des librairies dédiées à XSLT, les principaux navigateurs sont aussi équipés et on peut donc en Javascript réaliser une transformation depuis un navigateur.


Dans notre monde éditique, l'idéal est d'avoir un webservice ou une API Rest qui réalise cela avec en entrée le flux XML dans une chaîne (string) et l'URL d'un modèle (ici fichier xsl) et qui renvoie le HTML dans une chaîne.
La spécification est à sa version 3.0 à ce jour, mais son implémentation, notamment dans les navigateurs, s'arrêtent souvent à la version 1.0. Perso je ne vais pas plus loin que la version 1.0.
Transformer consiste le plus souvent à 4/5 lignes de codes, le plus complexe ma bonne dame, c'est le format XSL!
2 - XSL
présentation du langage et son intérêt en éditique
XSL c'est du XML, et un ensemble assez important de balises, avec un préfixe (donc un namespace dédié), xsl. Parmi les stars du box-office :
- xsl:stylesheet : balise principale d'une feuille de style (unique)
- xsl:template : déclare un template avec un nom ou un pattern. Si la racine de votre xml est zagawa, on lance la transformation de cette racine via : <xsl:template match="zagawa"> ... Le pattern est déclaré via 'match'. On peut aussi déclarer un template par son nom via l'attribut name. On a donc au moins un template par feuille de style, et on peut en avoir plusieurs. On peut appeler un template par son nom ou appeler les templates selon le contexte.
- xsl:if : l'intérieur de la balise est déclenchée si la condition dans l'attribut test est true
- xsl:choose : un peu comme le if mais en version switch
- xsl:variable : génère une variable soit à partir d'un noeud de l'arbre, soit en créant une nouvelle arborescence. Cette seconde possibilité permet de faire du mapping de données
- xsl:for-each : une boucle sur une partie de l'arboresence avec du XPath dedans
- xsl:value-of : 'sortir' une valeur, expression ou un calcul ; la balise la plus utilisée je dirais
- xsl:import et xsl:include : importer ou inclure un autre fichier xsl ! La différence entre les 2 est mince, mais dans un contexte éditique (ou autre) c'est là que la conception en mode composants réutilisables commence. Cela permet de créer un xsl pour le bloc adresse et de l'appeler dans tous les courriers avec un bloc adresse ! On mettra dans ces fichiers externes des xsl:template réutilisables du coup.
Il y a pas mal d'autres balises, plus ou moins utiles, mais les 2 dernières permettent vraiement de rendre la conception modulaire. A partir de là s'ouvre des possibilités de création de composants éditiques : modèles, sous modèles, chartes graphiques, gabarits, fonctions, ... au sein d'un référentiel.
Le XSL n'est pas le langage le plus drôle ni le plus facile à appréhender, sa courbe d'apprentissage peut rebuter, mais c'est clairement la langage de templating le plus évident à mon sens, car universel, standardisé et ... ouvert ! Je reste toujours stupéfait de voir les efforts développés pour réinventer des solutions pour afficher une page web à partir d'un modèle. Dans ma jeunesse j'ai joué avec asp, jsp, ... un bon gros mélange de code et de langage balisé, ... beurk. Et ça continue avec cette liste longue comme une grève de dockers (...) dans le monde Node.js :
Le gros défaut de XSL, c'est encore une fois sa verbosité. D'où l'intérêt de décomposer au maximum les modèles en templates et en composants. Le second défaut de la bête c'est la difficulté à débuguer, encore plus en multipliant les composants. Donc on multipliera les tests en cours de développement, et on restera aussi sobre que possible.
Perso, j'adore ce langage que j'utilise partout, pour faire mes factures, pour faire des slides ou graphiques d'avancement en gestion de projets, de la visualisation de XSD, de flux de données, ... Bien sûr je l'associe à son pote : HTML
3- HTML5 mon mari
... et CSS3 tant qu'on y est
Allez, encore un raccourci de langage, car HTML5 et CSS3 vont toujours de paire, car CSS3 n'existe pas (en fait cela désigne tout ce qui est après CSS2.1), donc sauf exception, HTML désignera l'emploi conjoint de HTML5, pour la structure, avec CSS3 pour l'affichage et la mise en page.
Le HTML a d'abord et surtout été créé pour diffuser de l'information; des documents avec des hyperliens, sur un écran de PC. Donc les notions de page, de recto-verso, de paysage vs portrait, de A4, ... on oublie. Ici on parle de taille d'écran, de résolution, d'orientation dynamique d'écran, de zoom, et autres avatars de la Galaxie Responsive Design. Oui, mais ... non.
Le CSS3 a apporté de nombreuses évolutions dont certaines nous intéressent dans la composition et la mise en page de documents. Je pense à FlexBox, Grid Layout, @media print ou @page qui vont nous permettrent de passer d'une page web à un document imprimable.

L'idée de base est de produire un html qui sera imprimé en PDF via la fonction imprimer du navigateur pour commencer, avec des pages bien gérées, des entêtes et pied de page, des marges, des tailles de papier et l'orientation qui se mettent en place nickel.
Pour la gestion des pages notre allié principal s'appelle ... Responsive Design. Ici le média qu'on teste est print :
@media print { .insec { page-break-inside: avoid; } }Dans cet exemple on indique que lors de l'impression (donc pas à l'écran mais c'est logique), les éléments de class insec, doivent si possible ne pas être splittés sur 2 pages. On y est ! Il existe aussi page-break-after et page-break-before qui peuvent aussi aider à forcer un saut de page.
Pour le déclenchement propre de l'impression on utilisera la directive @page :
@page { size: A4 portrait; margin: var(--pagemargin); }Ici on demande à ce que l'impression soit sur de l'A4, l'orientation en portrait et les marges "papier" dépendent d'une variable. Normalement les paramètres d'impression se calent sur ces valeurs. Il est aussi possible de piloter les veuves et orphelins au sein de @page.
Pour plus de détails sur @page :
Comme tout n'est pas rose dans la vie, les navigateurs ont un support assez faible de @page, et des pans de la specs ne sont pas implémentés, je pense aux blocs de marge qui auraient pu permettre de gérer les entêtes et pieds de page de manière élégante. Pire encore certains navigateurs, Firefox pour ne pas le citer, gère très mal @media print ; les éléments insécables ne le sont plus ! Donc exit Firefox dans les tests, perso je passe tout par Chrome (ou Chromium pour rester Open Source).
Le support de FlexBox à l'écran est trés bon sur tous les navigateurs, par contre je rencontre des effets indésirables en print. Pour arriver à un résultat satisfaisant je dois souvent jouer avec CSS3 et mettre en place des astuces, comme des calques via les propriétés position ( absolute vs relative ) pour superposer 2 objets dont les flux d'affichage sont indépendants (première page par exemple).
Mes 2 principaux soucis pour passer au print sont :
- les tableaux sur plusieurs pages
- les entêtes et pieds de page
Le principal défi des tableaux sur plusieurs pages sont la nécessaire répétition des entêtes de tableau à chaque page. J'ai longtemps réfléchi à une solution, sans en trouver car il n'y en a pas de simple, et surtout il n'y en a pas besoin (truc de fou!). En effet, j'ai découvert récemment qu'un tableau construit avec <table>, <thead>, <tbody>, ... génère automatiquement la répétition des entêtes sur plusieurs pages en print. L'enjeu est donc de rendre insécables les cellules. Facile ;)
Le second défi concernent les entêtes et pieds de page (header/footer par la suite). En théorie @page propose des blocs de marge qui répondaient en partie à notre problématique; mais ça ne marche pas (ô rage! ô désespoir!). Ma solution consiste à ajouter à la marge haute ou basse selon les cas, l'espace requis pour le header/footer, dans @page { margin : .... } , et de venir sur-imprimer le header/footer en post-compo.
Exemple : je prévois une marge d'impression de 10mm, je veux un header de 20mm sur chaque page. Ma directive @page contiendra donc :
margin : 10mm ; margin-top : 30mm;
Il faudra donc en post-composition "superposer" un pdf avec du contenu dans un header de 20mm de haut avec une marge haute de 10mm. Idem si on veut faire un footer.
On fait ça assez bien avec des librairies pdf open source :
- Itext
- PDFSharp
- ...
Les choses sont plus complexes si on a un header/footer différent selon les pages. Ma réponse expéditive est que la raison du print "papier" n'est pas la plus forte et que faire simple c'est bien aussi. Même réponse pour la gestion du recto/verso, si la cible est le pdf et la simplicité, on peut faire simple.
On est dans le compromis, et on va jongler avec des astuces. D'où le besoin de rendre les choses modulaires pour ne pas réinventer la charrue à chaque fois.
La raison majeure de l'utilisation du HTML+CSS sur d'autres solutions c'est que c'est un langage ultra répandu, documenté et surtout disposant d'un très large vivier de développeurs compétents. Entre chercher un développeur ayant 5 d'expérience sur une solution éditique propriétaire et chercher un développeur front HTML5/CSS3 avec 5 ans d'expérience, je pense que la seconde solution me paraît plus viable.
Tout n'est pas rose dans l'usage du HTML, on est d'accord, mais dans la majorité des cas, on peut sortir un modèle propre avec XSL+HTML+CSS3. Reste que générer un PDF propre de manière automatisée à partir de HTML n'est pas aussi simple.
4 - Conversion PDF
on arrive au dessert
A ce moment du repas, on a un HTML qu'on doit convertir. Déjà une bonne idée selon moi serait que le HTML embarque tout : CSS, médias (image surtout) et les polices. C'est possible avec les data urls (du base64 qui vient remplacer vos URLs) et l'usage des web-font :
Pour la conversion cela rend les choses plus simples sans risque de manquer d'une ressource qui serait inaccessible.
Jusqu'ici la production de notre PDF se faisait en "imprimant" notre HTML. L'avantage se situe au niveau du débugage, on peut voir le résultat intermédiaire en HTML, corriger les CSS via les outils de développeur (Ctrl+Maj+I) et avoir un apercu des pages rapidemment. Mais dans la vraie vie, tu envoies ton HTML à un serveur qui te renvoie ton PDF.
Il existe pas mal de librairies open source ou commercial qui convertissent du HTML en PDF. J'avoue ne jamais avoir été convaincu par ces librairies, mais les technos évoluent, les produits s'améliorent, donc ça peut changer.
De mon côté j'ai découvert Chrome Headless (ou Chromium Headless):
En gros on peut lancer Chrome en ligne de commandes pour lui faire faire des tests, des screenshots, ... ou imprimer un PDF: la classe à Dallas. L'avantage c'est que tu es cohérent avec ce que tu vois dans Chrome. L'inconvénient c'est que c'est de la ligne de commandes. Eventuellement en mode batch ça peut le faire. On génère les fichiers HTML dans un coin et ensuite on lance 10000 commandes Chrome Headless. D'expérience ça n'est pas efficace sur de petits volumes mais ça passe mais sur du lourd sauf à paralléliser les appels, ça pêche un peu. Et en transactionnel on oublie.
Bonne nouvelle il existe un projet Open Source (un vrai de vrai les gars) qui permet de piloter Chrome dans du Node.js :
 puppeteer
puppeteerOn ouvre un browser, une nouvelle page, on charge l'url du document HTML et on demande de sortir le chef d'oeuvre en PDF. On a même des options sur l'impression (cf. plus haut @page), voir sur un template header/footer, ... C'est du Node.js, donc asynchrone à mort. Mon idée c'est de prendre ça en générant un pool tournant de browsers en mémoire qui reçoit les demandes et les traite. Tout ça dans une API Rest : URL du HTML en entrée, PDF en base64 en retour par exemple.
Allez, encore plus loin, on peut Dockeriser le truc. Là on touche au sublime... Docker ? C'est quoi. Pour ceux qui était sur Mars les 10 dernières années, c'est un projet Open Source (et ça continue) qui permet de virtualiser une application, en réutilisant des couches déjà existantes. Plus besoin d'installer tout un système et tout le toutime, une ligne de commande ou un fichier .yml et c'est partie :

Et quand tu passes Docker à l'échelle en cluster, ça devient Kubernetes (pour simplifier).


Bon j'exagère au début on galère un peu avec Docker, mais c'est une technologie bien présente désormais, qui simplifie largement le déploiement. J'en reviens à ma pénurie de compétences IT/Infra sur l'éditique, installer et maintenir des serveurs avec une solution éditique, ça demande des compétences pas très utiles le reste du temps, les montées de versions, MCO et j'en passe c'est la guerre, au final tu appelles le support du fournisseur qui te réponds, ou pas ... Docker et Kubernetes ça devient le couteau suisse dans pas mal d'infra donc gain de temps et d'efficacité.
J'en reviens à Puppeteer, avec Docker tu peux créer une image de ton API Rest Node.js + Puppetter + pool de Chromium, et déployer N containers depuis cette image avec un reverse proxy devant et prendre en charge de grosses charges, vu qu'en plus ton truc est sans état ni dépendances (si on met toutes les ressources dans le HTML). Tout cela demande évidemment à être fait (ben oui), testé et benchmarké.
Dernier mot sur le reverse proxy, pour ma part j'use et abuse de NGinx, encore un projet Open Source (je suis chaud comme une baraque à frites là), qui fait frontal web et reverse proxy (et d'autres choses). Sauf erreur c'est le serveur web le plus utilisé au monde; il y a une version commerciale pour ceux que ça intéresse.

Dans notre big picture, NGinx peut servir pour accèder aux sources pour l'atelier de développement, pour accèder aux ressources et composants XSL, pour accèder au HTML intermédiaire, et donc à nos containers.
On a fait le tour, ouf , pas trop tôt. J'ai décrit les briques de base de ce qu'on peut faire, on utilise un maximum de standards connus, HTML5, CSS3, XML, XSL, ... des briques Open Source très répandues comme Docker ou NGinx, ou dédiées comme Puppeteer ou des libs PDF, et on arrive à une suite qui se tient, et surtout ne déroute pas trop les développeurs ou l'infra.
Tout n'est pas simple ou évident, à titre perso j'ai encore des tests bout en bout pour faire tourner ça, ça demande des compétences très variées, on doit parfois faire machine arrière.
Je finirai ma série avec un schéma globale, et je pense des retours sur les retours.
Hasta luego amigos



