
Editique + Open Source = ? (suite )

Ce post est la suite d'un premier post d'introduction sur le thème de l'usage de composants Open Source dans une solution Editique :
 Cysiph
Cysiph
 Cyril Stouck
Cyril Stouck
En relisant ce premier post sur l'Editique et l'Open Source , je m'aperçois que, par abus de langage, je mets sous l'appellation "Open Source" des briques certes ouvertes et "libres" mais de nature très différentes :
- des briques Open Source développées au sein de communautés, par des développeurs indépendants et/ou pour le compte d'une ou plusieurs organisations de natures diverses ( entreprises, ESN, gouvernements, ... ) et diffusées plus ou moins gratuitement via des licences plus ou moins permissives (LGPL,MIT,Apache, ...)
- des standards/normes ouverts par essence (HTML, CSS, XML, ... )
Évidemment ça n'est pas la même chose mais mon propos n'est ni de refaire l'histoire de l'Open Source, ni de choquer les puristes. Donc pour la suite je parlerai d'Open Source, de libre et d'ouvert pour désigner tout cela sans distinction.
En entrée : les données
XML, mon mari !
En 2024, 2 formats modernes et ouverts de flux s'offrent à nous : XML et JSON. Avec des qualités communes :
- largement utilisés
- souples : permet de représenter des formes variées de données (hiérarchie, tableau, .. )
- facilement lisible par un humain
- c'est du texte !
Des avantages particuliers :
- XML : une structure peut être contrainte et documentée par du XSD
- JSON : peu verbeux (vs XML ) , facilement ingérable par du Javascript (et d'autres) en tant qu'objet
Et quelques points faibles:
- XML : très verbeux
- JSON : pas simple à contraindre ou à documenter
J'exclus volontairement les autres formats de types csv, texte, ... qui offrent peu de souplesse et demande souvent un surdéveloppement afin d'être produits et lus. J'exclus aussi les requêtes directes vers des bases de données SQL ou gros systèmes car cela engendre à nouveau un surdéveloppement et surtout un fort couplage avec le schéma de base de données.
De plus nos flux JSON ou XML sont plutôt bien adaptés à 2 grands scenarii de production : batch avec dépôt de fichiers, et transactionnel via une api REST par exemple.
Le choix de la rédaction : le XML
JSON aurait pu être le candidat idéal, déjà car c'est la format le plus souvent utilisé dans les API REST, mais aussi par sa relative compacité par rapport au XML.
Je préfère le XML pour 2 raisons :
- comme déjà dit il est "documentable" et contraignable par du XSD (XML Schema Description) qui est lui même du XML
- on peut transformer du XML en d'autres formats texte (HTML, CSS, XML, SVG, ...) via une autre technologie de la galaxie XML : XSL-T, dont je parlerai plus tard.
Dans la majorité des projets éditiques sur lesquels j'ai travaillé, c'est ce format qui était utilisé; les autres formats étant beaucoup plus contraignant.
Ce choix est évidemment personnel, donc discutable, et j'imagine que de nombreux projets sans XML ont satisfaits leurs créateurs. Je pense à tous les cas hyper massifiés en banque notamment, où l'on doit envoyer des millions de documents sur des périodes réduites, les choix sont peut être restés sur du gros système qui donnait et donne toujours satisfaction.
Un exemple de ce que l'on peut faire avec du XSD pour documenter (et contraindre j'insiste) des flux XML :
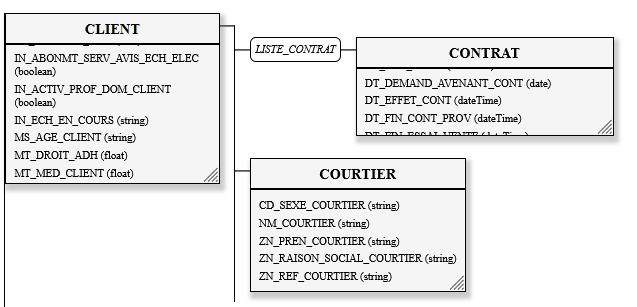
Comme on peut le voir, il est possible de visualiser les objets, les relations, les types qu'on trouve dans un fichier XSD, au départ particulièrement austère. Trop souvent les flux de données entrants ne sont pas documentés, ou très mal dans des fichiers Excel plus austère encore ;)
Il y a un peu de travail, mais pour moi c'est un incontournable des spécifications d'un modèle. Bien sûr l'idéal c'est de ne pas réinventer la poudre à chaque modèle, de bien réutiliser des notions récurrentes (ici Contrat et Client).
Pour la partie contrainte cela passe par quelques lignes de code :

 Pankaj
Pankaj
Voilà pour mon point du vue sur XML, le gros défaut c'est sa verbosité évidemment !
En sortie : PDF
Déjà le dessert ?
Avant de s'attaquer au reste de la cuisine, je voulais parler du format de sortie, le PDF. L'un des formats les plus répandus, il répond très bien à nos 2 grands types de sortie : le print et le digital. Les façonniers, routeurs, ... le prennent sans broncher et dans un monde digital c'est le gendre idéal : pour le stockage, l'affichage, l'impression locale et cerise sur le gâteau l'utilisation de signature électronique avec du PDF/A par exemple. Les plus audacieux me diront qu'en plus le format est éligible au statut de demi dieu de la facture électronique (Factur-X) ...
Bien sûr il reste encore des cas où d'autres formats, comme l'AFP, font mieux l'affaire comme les impressions hyper massifiées dont on a parlé, mais est-ce l'avenir ?
Ici on est bien sur un format ouvert qui fait l'unanimité dans quasiment tous les contextes.
Un dessert vite fait bien fait avant d'aller regarder en cuisine.
To be continued ...




